项目背景
原官方的canal单点消费处理实现作为数据库监听服务,在应对大型多数据库架构等重要场景下,随着后续业务发展,大数据量的处理,为提升canal消息处理及时性、处理速度,并且为保障系统稳定性、可维护性,优化重构canal消息处理机制实现横向扩展成为必要趋势。
项目目标
- 废弃现有canal官方单一节点消费运行处理模式
- 消息拆分到各个领域,实现canal消息按需配置生产和消费
项目价值
- 目前情况:
- **运维单一:**所有的数据库监听消息处理都在单一项目,各业务线改动点都需要改动、发布部署该项目,影响面较大
- **耦合性高:**代码依赖所有业务线以及oms等项目Dto,项目涉及业务知识领域较广,不利于专业求精
- **扩展性差:**当前处理数据量较大,单纯依靠增加服务器资源,不能完全解决消息处理及时性及处理速度
- **维护成本高:**需自行处理大并发量数据处理、大数据量分库分表存储等方案,系统稳定性研发维护成本较高
- 项目上线后:
- **系统安全性高:**在去中心化的应用中,生产消费消息直接对接阿里云MQ,利用现成的平台补偿、重试等机制,消息可靠性得到保障
- **可维护性高:**业务消息拆分到各自业务线,公共代码部分在成熟后作为基础工具处理器,整体系统架构更为简单,分散业务运维成本,现有专业业务知识研发维护,提升整体运营维护效率
- **系统性能好:**由于去中心化处理方式较传统处理方式更为简单与便捷,因此在大数据量处理同时进行时,去中心化的方式会节约资源
- **自主高效性:**去中心化的技术,点对点直接交互,使得高效率、无中心化代理、大规模的信息交互方式成为现实。横向扩展可增加topic、分表消息,消费端可根据自身性能调配服务器资源
技术调研
参考资料
架构思路
- 架构方案
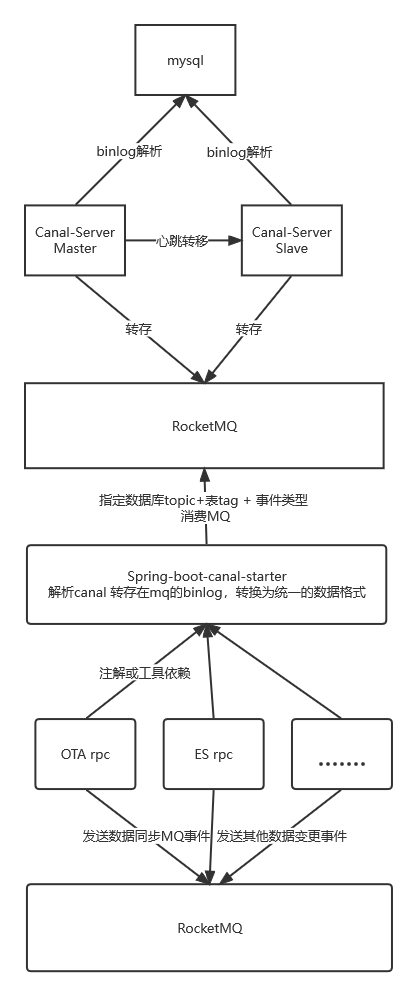
技术框架选型
- 阿里云RocketMQ暂不支持批量发送消息,当canal.mq.flatMessage = true时,会发送失败
- mq事务开始结束处理,消息ack问题。MQ消息处理 https://github.com/alibaba/canal/blob/master/example/src/main/java/com/alibaba/otter/canal/example/rocketmq/CanalRocketMQClientExample.java
- mq配置需 (>=1.1.5版本) rocketmq.tag=rocketmq的tag配置
- 自定义动态tag方式修改源码,利用动态topic逻辑调整tag
/** * 按 schema 或者 schema+table 将 message 分配到对应topic * * @param message 原message * @param defaultTopic 默认topic * @param dynamicTopicConfigs 动态topic规则 * @return 分隔后的message map */ public static Map<String, Message> messageTopics(Message message, String defaultTopic, String dynamicTopicConfigs) //修改发送消息 private void sendMessage(Message message, int partition)
消费tag过滤public static final String ROCKETMQ_SUBSCRIBE_FILTER = ROOT + "." + "subscribe.filter"; rocketMQConsumer.subscribe(this.topic, "ES_UPDATE_EVENT"); rocketMQConsumer.registerMessageListener(new MessageListenerOrderly()
- MQ配置案例
- 动态配置topic,预计9个topic
database_a:database_a_test\..*_order.*, database_b:database_b_test\..*_order.*, database_c:database_b_test\..*_order.*, database_d:database_b_test\..*_order.*, database_e:database_b_test\..*_order.*, database_f:database_b_test\..*_order.*,
- 动态配置tag,1个topic9个tag,按照动态topic模式修改源码实现
database_a:database_a_test\..*_order.*, database_b:database_b_test\..*_order.*, database_c:database_b_test\..*_order.*, database_d:database_b_test\..*_order.*, database_e:database_b_test\..*_order.*, database_f:database_b_test\..*_order.*,
过滤ddl数据
# binlog filter config canal.instance.filter.druid.ddl = true canal.instance.filter.query.dcl = true canal.instance.filter.query.ddl = true
- 动态配置topic,预计9个topic
- 关于mq顺序:https://help.aliyun.com/document_detail/117459.htm?spm=5176.smartservice_service_chat.help.dexternal.2290709a7Oh57w 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 同一信息在批量事务内
— 同一事务修改两个表数据,一条消息
set autocommit = 0; — //1是自动提交
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME +1 where ID=126828587192704;
UPDATE database_a_order_passenger set UPDATE_TIME = UPDATE_TIME +1 where ORDER_ID=126828587192704;
commit; — //或者rollback;– 每个事务修改单数据,分多条消息
set autocommit = 0; — //1是自动提交
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME -1 where ID=126828587192704;
commit; — //或者rollback;
UPDATE database_a_order_p set UPDATE_TIME = UPDATE_TIME -1 where ORDER_ID=126828587192704;
commit; — //或者rollback;— 一个事务修改全表数据,多条消息
set autocommit = 0; — //1是自动提交
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME -1 ;
commit; — //或者rollback;— 一个事务修改同一个订单,一条消息
set autocommit = 0; — //1是自动提交
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME -1 where ID=126828587192704;
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME +1 where ID=126828587192704;
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME -1 where ID=126828587192704;
UPDATE database_a_order set UPDATE_TIME = UPDATE_TIME +1 where ID=126828587192704;
commit; — //或者rollback;
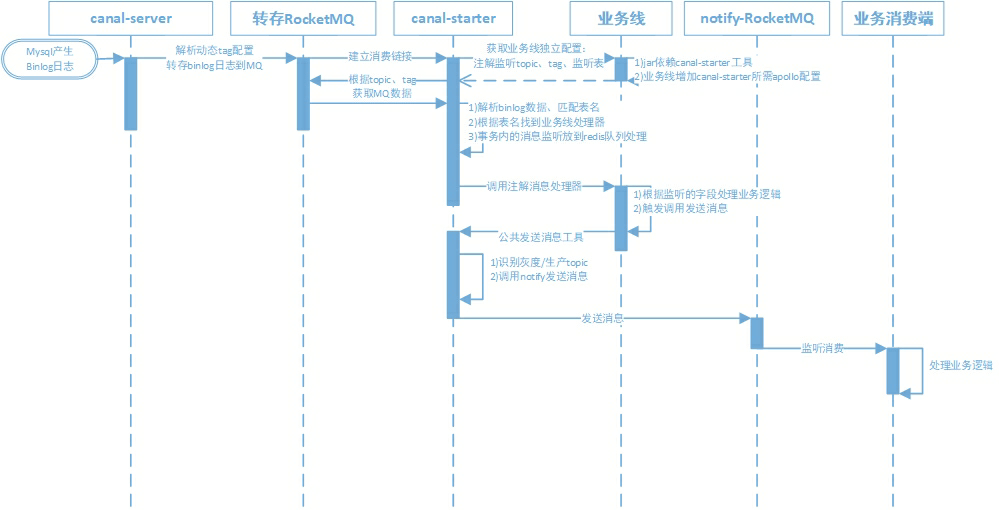
ES消息处理流程与架构
- 方案前提说明
1)确认使用rocketMQ
2)确定按照单topic多tag模式对接,修改源代码发布canal-server
3)事务内的消息发MQ处理方案?
(1)消费端构建一个Redis队列:判断事务开始,就放到redis队列中,直到结束,最大100条。然后取出队列合并处理
(2)改源码canal-server端过滤处理事务内的消息,调研改动方式
- 序列图
技术问题答疑
1、CanalMQ是如何保障服务异常或重启时的消息的一致性问题;
答:canal-server处理消息时会记录读取binlog日志的指针,服务重启时会从记录指针点开始继续处理
2、MQ的费用问题?
答:基础topic 2块钱,按多topic模式预计9个topic。2*9*30=540块/月
(需修改源码实现)按多tag模式,1个topic多个tag。 2*30=60块/月
消息量 82024764*0.001*3= ? 10 亿=2000块/月(当前16亿消息量)
替换省成本
3、如何减少转存到MQ的binlog数据量?
1)canal配置监听指定表
2)canal配置监听指定类型的binlog操作日志
3)可修改源码:过滤业务场景中所需要的业务操作数据
4)可以采用kafka来替代RocketMQ
4、CanalMQ如何保障binlog转存的顺序性?
答:
1)单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
2)多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
5、消费端如何保障处理的顺序性?
答:依赖消息生成端的顺序性,保证消费封装 处理线程的顺序
6、MQ没法批量获取消息,同一个事务内如果有多条操作记录的话,如何合并发送一次MQ通知?
1)消费端构建一个Redis队列?
2)改源码canal-server端过滤处理事务内的消息?
7、canalMQ方案与es-service 是否可以并行执行?
答:可以,只是会重复发送,灰度中可并行发送,长远是替换掉
8、ota rpc 的mq处理独立rpc服务? 单topic多tag模式
项目地址

![企业微信开发JAVA源码框架[weiwork]](https://www.bywei.cn/wp-content/themes/git-v11.2/timthumb.php?src=https://github.com/bywei/weiwork/raw/master/screenshot/banner.jpg&h=110&w=185&q=90&zc=1&ct=1)


